So its draft time in AFL at the moment and being a keen fan on all drafting I was a little disappointing with the coverage. Not because there were not people doing some interesting work. We had a great article on ABC by the guys over at HPN who were contributors to footballistics a great book for anyone who is interested in some numbers behind the game. But I just wished there were more!
Tony over at Matterofstats has been recently doing a great series of blog posts trying to classify players into positions based on their data.
So it would seem as though people are interested in players draft positions, what club they play for and their playing positions.
But I guess another question could be, if these blog posts are so interesting and presumebly useful to AFL clubs and fans why is there not more content?
My guess is that its mainly because the data isn’t readily available.
So lets make this data available for all from footywire and if the demand is there (which I suspect it will be) expect some integration to fitzRoy
Step One
First we have to find a page that contains the data we are after, for ease it would be best if all the information we wanted, say player name, club, height, weight, draft positon and playing position were available on the same page.
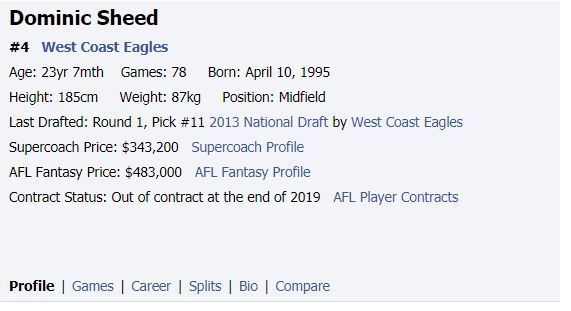
So lets go to footywire do some digging around and lets find a specific players page say Dominic Sheed.
Grand Final Hero
So Looking at the page, we can see there is a fair bit of information we would like. We want his height, weight, position and his draft position. Hopefully by following this example if you wanted to you could also get his supercoach price, fantasy price and his contract status.
Step 2
Install the R packages that we need.
library(tidyverse)## ── Attaching packages ─────────────────────────────────────────────────────────── tidyverse 1.2.1 ──## ✓ ggplot2 3.2.1 ✓ purrr 0.3.3
## ✓ tibble 2.1.3 ✓ dplyr 0.8.3
## ✓ tidyr 1.0.0 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.4.0## ── Conflicts ────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(rvest)## Loading required package: xml2##
## Attaching package: 'rvest'## The following object is masked from 'package:purrr':
##
## pluck## The following object is masked from 'package:readr':
##
## guess_encodinglibrary(stringr)
cbind.fill <- function(...){
nm <- list(...)
nm <- lapply(nm, as.matrix)
n <- max(sapply(nm, nrow))
do.call(cbind, lapply(nm, function (x)
rbind(x, matrix(, n-nrow(x), ncol(x)))))
}Step 3 A single example
I find its best to just scrape a single page then we can figure out how to automate the scrape so we can get a list of players.
So just looking at Dominic Sheed lets go step by step and get some of his information.
Step 3a Read in the html
page<-read_html(x="https://www.footywire.com/afl/footy/pp-west-coast-eagles--dominic-sheed")
page## {html_document}
## <html>
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body onload="pushContent('Player Profile', 'Dominic Sheed');showMemberSt ...So now we have the content of our page, we essentially have to filter out the information we don’t want and leave the information we do want in hopefully a nice table so we can analyse it.
Step 3b Get the player name
player<- page%>%
html_nodes("#playerProfileName")%>%
html_text()
player## [1] "Dominic Sheed"We take the html of the page and we find the information we want to extact into our table using html_nodes and html_text.
While it looks a little weird the html_nodes("#playerProfileName") its fairly simple to do using selector gadget
Step 3c Get the rest of the information
playing.for<- page%>%
html_nodes("#playerProfileTeamDiv a b")%>%
html_text() %>% as.tibble()## Warning: `as.tibble()` is deprecated, use `as_tibble()` (but mind the new semantics).
## This warning is displayed once per session.playing.for## # A tibble: 1 x 1
## value
## <chr>
## 1 West Coast Eaglesnumber<- page%>%
html_nodes("#playerProfileTeamDiv > b")%>%
html_text() %>% as.tibble()
number## # A tibble: 1 x 1
## value
## <chr>
## 1 #4 weight<-page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Weight:).*(?=Position:)"))%>%as.tibble()
weight## # A tibble: 1 x 1
## value
## <chr>
## 1 " 87kg "height<-page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Height:).*(?=Weight:)"))%>%as.tibble()
height## # A tibble: 1 x 1
## value
## <chr>
## 1 " 185cm "draft_position <- page%>%
html_nodes("#playerProfileDraftInfo")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Drafted: ).*(?=by)"))%>%as.tibble()
draft_position## # A tibble: 1 x 1
## value
## <chr>
## 1 Round 1, Pick #11 2013 National Draftclub_drafted <- page%>%
html_nodes("#playerProfileDraftInfo a+ a")%>%
html_text()%>%str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_remove(".*by") %>% as.tibble()
club_drafted## # A tibble: 1 x 1
## value
## <chr>
## 1 West Coast Eaglesposition <- page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_remove(".*Position: ")%>%
str_squish() %>% as.tibble()
sc_price<-page%>%
html_nodes("#playerProfileSupercoach")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Price:).*(?=Supercoach Profile)"))%>%as.tibble()
sc_price## # A tibble: 1 x 1
## value
## <chr>
## 1 " $441,000 "af_price<-page%>%
html_nodes("#playerProfileDreamteam")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Price:).*(?=AFL Fantasy Profile)"))%>%as.tibble()
af_price## # A tibble: 1 x 1
## value
## <chr>
## 1 " $591,000 "This step has a few tricky steps usually revolving around how to deal with text data that isn’t neat.
So lets go through some of them with some additional commentary.
str_replace_all("[\r\n]" , "") and str_squish Why did we have to use this?
We first use this to get the weight of the player.
What happens if we don’t use str_replace_all and str_squish
page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
# str_squish()%>%
str_extract(pattern =("(?<=Weight:).*(?=Position:)"))%>%as.tibble()## # A tibble: 1 x 1
## value
## <chr>
## 1 " 87kg "page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_extract(pattern =("(?<=Weight:).*(?=Position:)"))## [1] NAWe get an NA even though we are using str_extract trying to get the text between Weight: and Position:
So the next step would be to do some investigation.
One of the best things about %>% is that we can run bits of code piecewise and easily see what it returns.
page%>%
html_nodes("#playerProfileData2")%>%
html_text()## [1] "\nHeight: 185cm \nWeight: 87kg \nPosition:\n Midfield\n "So what we can see is that we have these \n and long spaces between things we want. So this is why we use str_replace_all("[\r\n]" , "") and str_squish to get something a lot nicer like follows.
page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Weight:).*(?=Position:)"))%>%as.tibble()## # A tibble: 1 x 1
## value
## <chr>
## 1 " 87kg "The next thing that might look a little weird is the str_extract and the str_remove
So lets think about a sentence or a bunch of text information like we have just scraped from Dom Sheeds page.
We might want one of essentially 3 situations
- All the text up to a certain word
- All the text between two words
- All the text after a word
Lets use as our example the scrape we have just done
page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()## [1] "Height: 185cm Weight: 87kg Position: Midfield"which should return us
“Height: 185cm Weight: 87kg Position: Midfield”
- All the text up to a certain word
If we wanted only height, which we do we would extract all the text up until the word Weight.
page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =(".*(?=Weight:)"))## [1] "Height: 185cm "The .* that just refers to what you want to extract then the next part is well when do we stop, we stop once we reach Weight ?=Weight:)
- All the text between two words
The next part of the example is, lets say you don’t want the word height, but instead you wanted what was inbetween the words Height: and Weight: i.e. the actually measurement.
You can do that as follows.
page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Height:).*(?=Weight:)"))## [1] " 185cm "The first thing is we need to find the word Height: which we do using (?<=Height:) then we place our .* for the text we actually want to pull out and then we stop once we hit Weight: (?=Weight:)
- All the text after a word
Lets look at our original text. "Height: 185cm Weight: 87kg Position: Midfield"
What we want now is the position of the player, which thankfully always appears after the string Position:
So lets think about it we want to get the string .* after Position:
page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_remove(".*Position: ")%>%
str_squish()## [1] "Midfield"Last step make it into a function
If we were to just do Dom Sheed alone, our script would look something like this.
page<-read_html(x="https://www.footywire.com/afl/footy/pp-west-coast-eagles--dominic-sheed")
player<- page%>%
html_nodes("#playerProfileName")%>%
html_text()
player## [1] "Dominic Sheed"playing.for<- page%>%
html_nodes("#playerProfileTeamDiv a b")%>%
html_text() %>% as.tibble()
playing.for## # A tibble: 1 x 1
## value
## <chr>
## 1 West Coast Eaglesnumber<- page%>%
html_nodes("#playerProfileTeamDiv > b")%>%
html_text() %>% as.tibble()
number## # A tibble: 1 x 1
## value
## <chr>
## 1 #4 weight<-page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Weight:).*(?=Position:)"))%>%as.tibble()
weight## # A tibble: 1 x 1
## value
## <chr>
## 1 " 87kg "height<-page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Height:).*(?=Weight:)"))%>%as.tibble()
height## # A tibble: 1 x 1
## value
## <chr>
## 1 " 185cm "draft_position <- page%>%
html_nodes("#playerProfileDraftInfo")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Drafted: ).*(?=by)"))%>%as.tibble()
draft_position## # A tibble: 1 x 1
## value
## <chr>
## 1 Round 1, Pick #11 2013 National Draftclub_drafted <- page%>%
html_nodes("#playerProfileDraftInfo a+ a")%>%
html_text()%>%str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_remove(".*by") %>% as.tibble()
club_drafted## # A tibble: 1 x 1
## value
## <chr>
## 1 West Coast Eaglesposition <- page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_remove(".*Position: ")%>%
str_squish() %>% as.tibble()
sc_price<-page%>%
html_nodes("#playerProfileSupercoach")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Price:).*(?=Supercoach Profile)"))%>%as.tibble()
sc_price## # A tibble: 1 x 1
## value
## <chr>
## 1 " $441,000 "af_price<-page%>%
html_nodes("#playerProfileDreamteam")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Price:).*(?=AFL Fantasy Profile)"))%>%as.tibble()
af_price## # A tibble: 1 x 1
## value
## <chr>
## 1 " $591,000 " player_information <- cbind.fill(player, playing.for, number, weight, height,draft_position, club_drafted, position, sc_price, af_price)
player_information <- as.tibble(player_information)So that’s great it has all the information we want, the information we are after is in the same spot across pages so all we need to do is go to each individual page and run the same script and we we get all the tables to join.
Sounds a bit annyoing hey?
So it would be better to get a list of urls and for each of those urls we take from the page the information we are after. That sounds a lot better right?
library(rvest)
library(tidyverse)
library(purrr)
library(xml2)
library(stringr)
url<-"https://www.footywire.com/afl/footy/ft_players"
link<-read_html(url)%>%
html_nodes("br+ a , .lnormtop a:nth-child(1)")%>%
html_attr("href")
url_players<-str_c("https://www.footywire.com/afl/footy/",link)
cbind.fill <- function(...){
nm <- list(...)
nm <- lapply(nm, as.matrix)
n <- max(sapply(nm, nrow))
do.call(cbind, lapply(nm, function (x)
rbind(x, matrix(, n-nrow(x), ncol(x)))))
}
player_info <- function(x){
# page <- read_html(x)
page<-read_html(x)
player<- page%>%
html_nodes("#playerProfileName")%>%
html_text()
# player
playing.for<- page%>%
html_nodes("#playerProfileTeamDiv a b")%>%
html_text() %>% as.tibble()
# playing.for
number<- page%>%
html_nodes("#playerProfileTeamDiv > b")%>%
html_text() %>% as.tibble()
# number
weight<-page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Weight:).*(?=Position:)"))%>%as.tibble()
# weight
height<-page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Height:).*(?=Weight:)"))%>%as.tibble()
# height
draft_position <- page%>%
html_nodes("#playerProfileDraftInfo")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Drafted: ).*(?=by)"))%>%as.tibble()
# draft_position
club_drafted <- page%>%
html_nodes("#playerProfileDraftInfo a+ a")%>%
html_text()%>%str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_remove(".*by") %>% as.tibble()
# club_drafted
position <- page%>%
html_nodes("#playerProfileData2")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_remove(".*Position: ")%>%
str_squish() %>% as.tibble()
sc_price<-page%>%
html_nodes("#playerProfileSupercoach")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Price:).*(?=Supercoach Profile)"))%>%as.tibble()
# sc_price
af_price<-page%>%
html_nodes("#playerProfileDreamteam")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Price:).*(?=AFL Fantasy Profile)"))%>%as.tibble()
# af_price
playerbirthday<-page%>%
html_nodes("#playerProfileData1")%>%
html_text()%>%
str_replace_all("[\r\n]" , "")%>%
str_squish()%>%
str_extract(pattern =("(?<=Born:).*(?=Origin:)"))%>%as.tibble()
#
player_information <- cbind.fill(player, playing.for, number, weight, height,draft_position, club_drafted, position, sc_price, af_price,playerbirthday)
player_information <- as.tibble(player_information)
#combine, name, and make it a tibble
player_information <- cbind.fill(player, playing.for, number,
weight, height,draft_position, club_drafted, position,
sc_price, af_price,playerbirthday)
player_information <- as.tibble(player_information)
# print(x)
# return(x)
return(player_information)
}
footywire <- purrr::map_df(url_players, player_info)
names(footywire) <- c("player", "club", "number","weight","height", "draft_position", "club_drafted",
"position","sc_price", "af_price","playerbirthday")Some of you might notice that this post has been updated and that the script has changed. That is because footywire has changed structure. Luckily, thanks to selecter gadget all I had to change was what was in html_nodes(). Have also updated for players birthdays.